
How Retailers Win Visibility in ChatGPT and AI Search
AI-driven search is changing how products are found online. Traditional keyword optimization is no longer enough. To stay competitive, retailers must focus on enriched product feeds that provide detailed, machine-readable data for AI systems like ChatGPT. Here’s what you need to know:
- AI prioritizes intent over keywords: Systems analyze structured product data to recommend items based on customer needs, not just keyword matches.
- Product feeds must include detailed attributes: AI looks for specifics like materials, use cases, and compatibility to confidently recommend products.
- Standard feeds aren’t enough: Basic feeds designed for platforms like Google Shopping lack the data AI needs for reasoning and recommendations.
- Enriched feeds drive results: Retailers using enriched data see higher visibility, better recommendations, and increased revenue.
How LLMs and AI Search Change Product Discovery
Traditional search engines worked by matching keywords in a query to keywords on a webpage. AI systems, however, take this a step further by interpreting the meaning behind a query. Instead of relying solely on keyword matches, these systems analyze the intent behind a customer’s question and determine which products align with that need. This evolution requires enriched product feeds filled with detailed, machine-readable data, allowing AI to grasp intent effectively.
This shift from keyword indexing to intent-driven reasoning has transformed how products are discovered. For example, if someone asks ChatGPT, “What’s the best running shoe for trail running in wet conditions?” the system doesn’t just look for pages with those exact words. It evaluates structured data to identify shoes with features like waterproof materials, aggressive tread patterns, and trail-specific designs. Without this machine-readable data, even the most suitable products might not surface. This transition highlights the importance of conversational and semantic search capabilities in today’s AI-driven world.
Conversational AI in Search
Conversational AI enables customers to interact with search systems in a more natural way. Instead of guessing the right keywords, users can now ask nuanced questions like, “I need a gift for someone who loves cooking but has a small kitchen” or “What’s a good substitute for this product that ships faster?” These systems understand context, intent, and subtle nuances in language.
This approach demands a new way of managing product data. A staggering 87% of AI recommendations come from structured feed data, not real-time web crawling. This makes the product feed a critical source of truth. For instance, OpenAI‘s product feed specification includes features like enable_search (to control visibility in ChatGPT) and enable_checkout (to facilitate in-app purchases). Retailers who treat their product feeds as static inventory lists miss the chance to provide the detailed context AI systems need to make confident recommendations. By prioritizing natural language interactions, the focus shifts from simple keyword overlap to understanding semantic relationships.
Semantic Understanding vs. Keyword Matching
Semantic understanding goes beyond matching words to grasp the meaning behind them. For instance, a customer searching for “eco-friendly water bottle” might still find relevant results even if the product description doesn’t include the term “eco-friendly.” This is possible if the product feed includes attributes like material_cert: organic_cotton or sustainability_rating: high. AI connects related concepts to infer relevance.
Traditional keyword-based systems often fail in this regard, with 30% of e-commerce searches not delivering relevant results. Products that meet customer needs may remain hidden simply because their descriptions lack machine-readable attributes. One global retailer addressed this by using multimodal AI to analyze product images alongside text, resulting in 3x more searchable data and an 8.66% increase in conversion rates, which translated into over $25 million in annualized revenue impact. The improvement wasn’t due to better marketing copy but richer, structured product data that AI could interpret and act upon. Unlike traditional feeds, this enriched data bridges the gap between static keywords and dynamic customer intent.
“Instead of describing your products to a search engine, you’re describing them to an AI that can reason about them. That means we’re no longer just optimizing for retrieval, we’re engineering for understanding.” – Mike King, Founder and CEO, iPullRank
Why Standard Product Feeds Fail in ChatGPT and AI Commerce
Retailers often rely on product feeds designed for platforms like Google Shopping. While these feeds work well for keyword matching and ad targeting, they fall short when it comes to supporting AI systems that need to analyze and reason about products. This mismatch means missed opportunities for visibility and recommendations. If your product data isn’t compatible with a large language model (LLM), your products won’t show up in recommendations – no matter how competitive your prices or strong your brand is. This issue not only affects product discovery but also disrupts the seamless data integration that AI relies on for accurate recommendations.
The lack of detail in standard feeds further limits AI’s ability to distinguish between similar products. For example, if a customer asks ChatGPT for “a running shoe for trail running in wet conditions”, the AI looks for specific attributes like waterproof materials, tread patterns, or trail-specific designs. Without these details in the feed, even the ideal product might not appear. In fact, incomplete product data contributes to the failure of up to 30% of commerce searches.
Another challenge is fragmented product data. Traditional systems often split information like pricing, inventory, and customer reviews into separate feeds. However, AI platforms require a unified view to generate context-rich recommendations. When data is scattered, AI struggles to connect the dots between product features, performance, and availability. This fragmentation makes it difficult to build the confidence scores essential for reliable recommendations.
Standard feeds also face issues with overly broad categories and inconsistent formatting. For instance, a generic label like “Furniture” doesn’t provide the level of detail AI needs. A more specific taxonomy – such as “Furniture > Cabinets > Dressers” – enables AI to apply category-specific filters and match products more effectively. Additionally, inconsistencies in units of measurement (e.g., “in” vs. “inches”) or vague descriptions (e.g., “Ocean Breeze” instead of “Texturizing sea salt spray”) can confuse AI systems, which depend on precise, machine-readable data. Enriched feeds address these issues by offering detailed, standardized, and well-structured data that AI can process with confidence.
What Basic Product Feeds Are Missing
Traditional product feeds were built for human users browsing through search engines, assuming customers would click on product pages for more information. In contrast, AI systems rely entirely on structured data to make decisions. If a feed lacks key attributes, the AI may skip over the product entirely, favoring competitors with more complete data.
Basic feeds usually include a product ID, title, price, image URL, and a link. Some might add a short description or a broad category. However, they rarely include the detailed attributes – like material composition, compatibility, specific use cases, care instructions, or performance metrics – that are crucial for handling nuanced, conversational queries.
Another major limitation is update frequency. Standard feeds often refresh every 24 hours, which is too slow for the real-time demands of AI commerce. Outdated data can lead to errors like “product unavailable”, damaging a retailer’s reliability in the AI ecosystem. With Gartner forecasting that by 2030, 20% of all transactions will occur through AI platforms or agents, real-time data synchronization is quickly becoming a must-have.
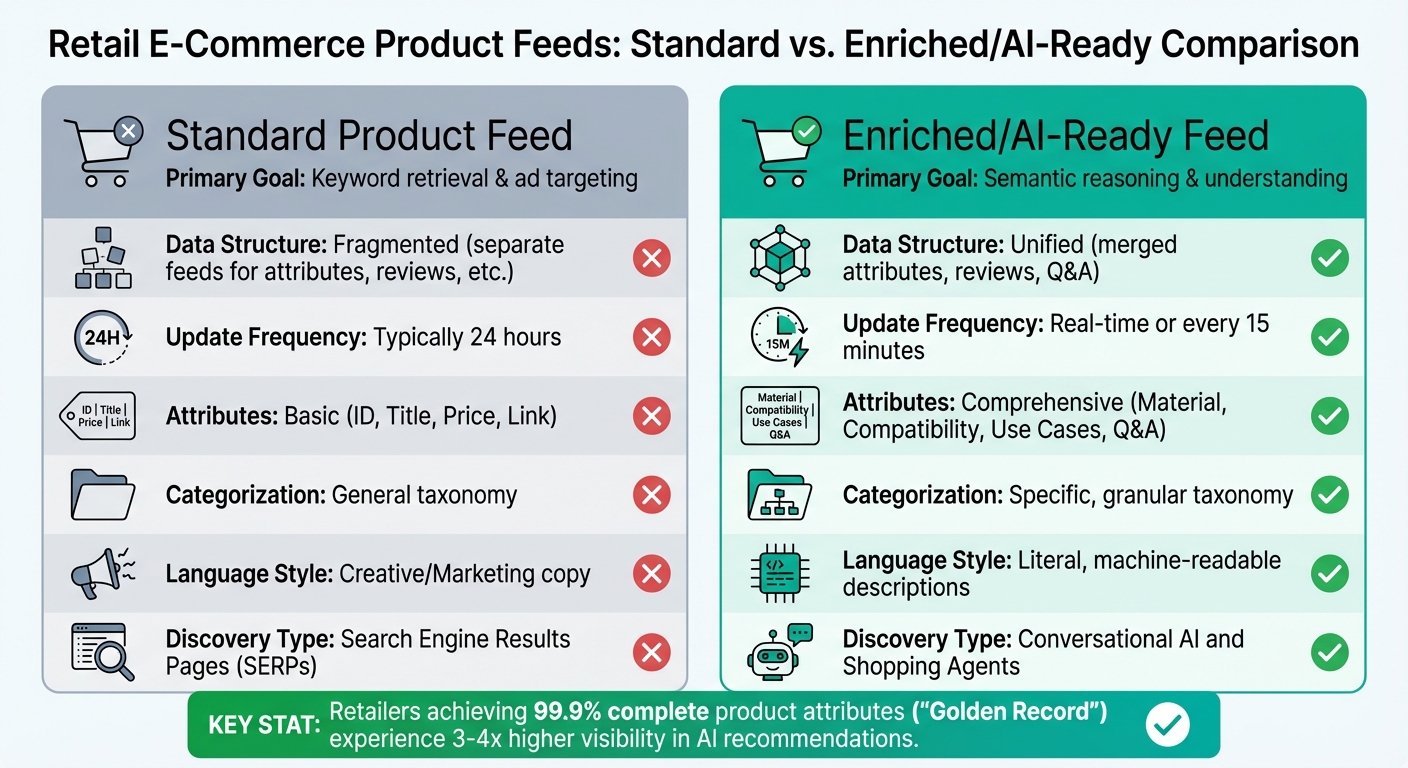
Standard vs. Enriched Feeds: A Comparison
The shift from standard product feeds to enriched, AI-ready feeds involves more than just adding extra fields. It’s about transitioning from basic keyword retrieval to enabling AI systems to reason and understand. Here’s how they compare:
| Feature | Standard Product Feed | Enriched/AI-Ready Feed |
|---|---|---|
| Primary Goal | Keyword retrieval and ad targeting | Semantic reasoning and understanding |
| Data Structure | Fragmented (separate feeds for attributes, reviews, etc.) | Unified (merged attributes, reviews, and Q&A) |
| Update Frequency | Typically 24 hours | Real-time or every 15 minutes |
| Attributes | Basic (ID, Title, Price, Link) | Comprehensive (Material, Compatibility, Use Cases, Q&A) |
| Categorization | General taxonomy | Specific, granular taxonomy |
| Language Style | Creative/Marketing copy | Literal, machine-readable descriptions |
| Discovery Type | Search Engine Results Pages (SERPs) | Conversational AI and Shopping Agents |
Retailers that achieve a “Golden Record” – where 99.9% of product attributes are complete – experience 3–4x higher visibility in AI recommendations compared to those with incomplete data. This isn’t about manipulating the system; it’s about making product data thorough, accurate, and machine-readable so AI can confidently recommend products.
One real-world example comes from January 2026, when a global retailer adopted Lucidworks Data Enrichment powered by multimodal generative AI. By analyzing product images and text, the retailer increased searchable data by 3x and achieved an 8.66% uplift in conversion rates, resulting in over $25 million in annualized revenue. The success came from addressing the gaps left by standard feeds, enabling AI to understand and recommend products it previously couldn’t.
What Product Feed Enrichment Actually Means
Product feed enrichment involves adding AI-generated attributes, relationships, and context to raw product data, making it both machine-readable and easily discoverable by AI search engines and large language models (LLMs). Unlike older methods of feed optimization, which often relied on basic techniques like field mapping or keyword stuffing, enrichment transforms raw data into structured, detailed information that aligns with how consumers search and interact.
Traditional optimization assumes a human will click through to a product page. Enrichment, on the other hand, operates under the idea that AI systems will make decisions based entirely on the feed data. If the attributes are incomplete, AI cannot reliably recommend products.
This shift challenges retailers to think beyond just basic identifiers like titles or prices. Enrichment incorporates tangible attributes (e.g., materials, dimensions) and contextual details (e.g., style, intended use – think “boho chic” or “wedding guest attire” – and situations like “beach-friendly”). Modern enrichment also uses multimodal AI, which analyzes product images alongside text to extract missing attributes that may not be included in the original product specifications.
“Search is often treated as a relevance problem. In reality, it’s a data problem.”
– Rishi Setia, Sr. Product Manager of AI, Lucidworks
The ultimate aim is to create machine-readable content that meets the expectations of AI-powered platforms, ensuring that AI systems can interpret and recommend products with confidence. This isn’t about tricking AI – it’s about ensuring the data is accurate, complete, and structured.
Core Elements of Product Feed Enrichment
Enriched product feeds go far beyond the basics like product ID, title, price, and image URL. They include detailed attributes that help AI understand not just what a product is, but also how it’s used, who it’s for, and what it complements. Key elements of enrichment include:
- Use cases: For example, “ideal for trail running in wet conditions.”
- Material details: Such as “waterproof Gore-Tex upper.”
- Compatibility: Like “works with iPhone 14 and later.”
- Additional details: Including performance metrics or care instructions, e.g., “battery life: up to 10 hours.”
- Variants: Covering size, color, or finish options.
These enriched attributes allow AI to respond to more nuanced, conversational queries that typical product feeds might overlook.
For example, Lucidworks shared in January 2026 that a global retailer using their Multimodal Data Enrichment system achieved an 8.66% boost in conversion rates and generated over $25 million in annualized revenue. The system tripled the amount of searchable data by automatically creating more specific subcategories and richer descriptions from both images and text.
By using natural language that mirrors how customers speak, enriched feeds bridge the gap between product descriptions and customer intent. For instance, swapping out merchant-specific terms like “thin straps” for more customer-friendly phrases like “spaghetti straps” better aligns with conversational AI. Similarly, standardizing units of measurement – for example, consistently using “in” instead of mixing “in” and “inches” – helps prevent AI misinterpretation.
Building Complete Feeds, Not Gaming AI Systems
Retailers must prioritize data integrity over trying to outsmart AI systems. Enrichment is about filling in gaps and improving data accuracy to help AI make better recommendations. Attempts to game the system with misleading attributes or keyword stuffing can harm credibility and effectiveness in AI-driven ecosystems.
Consider this: up to 30% of searches fail due to incomplete product data, and nearly 70% of shoppers abandon carts because of unclear or missing product information. By addressing these issues, enriched feeds create a seamless experience across all platforms – from AI-powered tools like ChatGPT to on-site search and recommendation engines. This positions enrichment as a transformative strategy, equipping retailers to thrive in an AI-driven commerce landscape.
How Synthetic Data Generation Fills Missing Catalog Intelligence
As the shift from traditional data feeds to enriched, machine-readable formats picks up speed, many retail catalogs remain incomplete by nature. Suppliers often provide only the basics, while internal teams add what they can. The result? Missing details, inconsistent terminology, and data gaps that make it harder for AI to discover and recommend products effectively. Synthetic data generation steps in to solve this issue by using AI to automatically create the missing product intelligence that large language models (LLMs) rely on to interpret and recommend products accurately.
This isn’t about inventing details – it’s about using multimodal generative AI to analyze existing data, such as images, sparse text, and attributes, to fill in the blanks. The aim is to convert incomplete supplier data into machine-readable product intelligence that reflects how customers search and how AI systems process information. This method addresses the widespread inconsistencies often found in large retail catalogs.
Fixing Data Gaps in Large Retail Catalogs
Retailers managing tens of thousands of SKUs frequently encounter incomplete or inconsistent product data. A product might have a title and price but miss key details like material, battery life, compatibility, or intended use. When LLMs face such sparse data, they struggle to recommend products due to a lack of context about what the product is or who it’s for.
Take, for example, a global retailer that, in January 2026, adopted Lucidworks Data Enrichment to tackle this exact challenge. By leveraging multimodal generative AI to analyze product images alongside existing text, the system was able to generate three times more searchable data and significantly improve recall for ambiguous categories. The initiative delivered an 8.66% increase in conversion rates and a projected annual revenue boost of over $25 million.
This process works by extracting attributes from product images that text-only feeds often overlook – details like style, patterns, color variations, and visual context. It also standardizes data by unifying measurement units (e.g., aligning “in” with “inches”) and resolving ambiguous terminology. The outcome is a catalog where every product is equipped with structured, complete data, enabling AI systems to make precise recommendations.
Better Product Understanding Through Synthetic Data
Synthetic data generation doesn’t just fill in gaps – it also deepens product insights. Beyond basic attributes, AI systems need to understand how a product is used, who it’s for, and what it complements. This requires enriching the data with contextual details like use cases, compatibility, and performance metrics.
For instance, instead of a generic description like “waterproof jacket”, synthetic data generation might add specifics such as “ideal for trail running in wet conditions”, “features Gore-Tex upper”, and “includes battery-powered heating elements with a 10-hour runtime.” These enriched attributes allow AI to handle more nuanced, conversational queries that standard product feeds would miss.
By transforming incomplete data into rich, synthetic intelligence, retailers can move beyond basic keyword matching to true AI-driven discovery. As Rishi Setia, Sr. Product Manager of AI at Lucidworks, explains:
“Search is often treated as a relevance problem. In reality, it’s a data problem”.
Synthetic data generation addresses this data issue on a large scale, making retail catalogs not just complete but also understandable to AI systems.
How Reasoning Systems Build Better Product Attributes and Relationships
Using synthetic data generation helps fill in missing data, but truly understanding product relationships requires reasoning systems. Together, these tools ensure product feeds are not just complete but also meaningful. Instead of merely plugging gaps, reasoning systems uncover connections, deducing context, intent, and commercial relationships that standard feeds often miss. They go beyond isolated product details to grasp how items interact – whether they complement, substitute, or enhance one another – in ways that matter to both consumers and AI systems.
Reasoning systems achieve this by leveraging graph-based reasoning, treating products as interconnected entities. These connections act as predictive features that reveal patterns like “frequently bought together” or “suitable substitutes” – patterns that flat, unstructured product feeds fail to capture. For example, when asked about specialized outdoor gear, an AI system must assess the context of the products rather than just match keywords. This ability to reason forms the backbone of mapping meaningful relationships between products.
Mapping Contextual Relationships Between Products
Reasoning systems excel at identifying and mapping relationships, turning static catalogs into dynamic, intelligent networks. They can differentiate between genuine product variants, like different sizes or colors, and entirely separate items, ensuring accurate connections. This capability is key to establishing cross-sell and substitute mappings. By analyzing data like purchase trends, product attributes, and semantic signals, these systems determine which items complement each other or can serve as alternatives. They achieve this through multimodal data fusion, combining insights from product images, descriptive text, and metadata. The result? A catalog where products are no longer isolated but interconnected, creating a richer shopping experience.
Beyond just mapping relationships, reasoning systems push product intelligence further by transforming basic attributes into actionable insights.
Adding Product Intelligence Beyond Keywords
Traditional product feeds often rely on simple keyword matching, but reasoning systems focus on deeper meaning, intent, and relevance. They strip away vague marketing terms like “best-in-class” and replace them with precise, measurable attributes that are easier for AI to understand. For instance, instead of generic phrases, they use specifics like “Gore-Tex material”, “30-hour battery life”, or “iPhone 15 compatibility”. This shift from promotional language to structured data makes product catalogs far more accessible to large language models (LLMs) and other AI systems.
The improvement in accuracy is dramatic. Systems grounded in clear business logic – semantic grounding – achieve 90% accuracy in generating correct queries, compared to just 51% for LLMs that lack such grounding. JP Tucker, Founder of Optidan AI, emphasizes this point:
“AI systems care about meaning, relationships, and context. Feed compliance alone does not deliver that.”
Reasoning systems also enable collaborative AI orchestration, where AI agents break down complex customer needs into actionable steps. For example, if a customer’s preferred product is out of stock, an AI agent can analyze shared attributes, performance metrics, and customer intent to suggest suitable alternatives. This advanced reasoning turns product feeds into powerful decision-making tools, driving visibility, discovery, and revenue across AI-powered platforms. By moving from basic keyword matching to structured, context-aware intelligence, these systems reflect the broader evolution of AI in enhancing product discovery and visibility.
Why Cross-Sell and Substitute Mappings Matter in LLM-Driven Commerce
Cross-sell and substitute mappings take enriched product attributes a step further, turning raw data into actionable insights that can directly influence revenue. By leveraging these mappings, product feeds become more than just lists – they become dynamic sources of relationship data that AI can use to meet actual customer needs. Imagine a shopper asking, “What are better options for X?” or “What do I need to make Y work?” For AI to provide meaningful answers, it must understand product relationships – what complements what, what can replace what, and the reasons behind it. Without these mappings, even the most advanced large language models (LLMs) are left relying on basic keyword matching, which lacks the context needed to drive conversions.
The shift from simple information retrieval to reasoning changes the game entirely. As Mike King, Founder and CEO of iPullRank, puts it:
“We’re no longer just optimizing for retrieval, we’re engineering for understanding”.
This level of understanding hinges on structured relationship data. Fields like relationship_type allow AI to grasp the role of a product within a specific scenario. Instead of merely acknowledging that a product exists in a catalog, AI can explain why it matters in a given context.
How AI Responds to Complex Customer Queries
Cross-sell and substitute mappings enable AI to address detailed, conversational queries that traditional search engines can’t handle. For example, if a customer asks, “Does this come in red?” the AI needs to recognize that different colors are variants of the same product, not unrelated items. Similarly, when a product is out of stock, substitute mappings can step in to suggest relevant alternatives, reducing the risk of abandoned shopping sessions. These alternatives are often based on shared attributes or performance metrics, ensuring relevance. This capability is crucial, especially as AI-driven orders from search and recommendations have surged 15x since early 2025.
Precision in implementation is key. Retailers must adopt consistent, specific language for attributes so AI can make accurate comparisons. For instance, describing a product as having a “30-hour battery life” is far more useful than vague terms like “long-lasting battery.” Additionally, grouping all variants (e.g., different colors or sizes of the same shirt) under a single parent ID ensures that AI understands these as related, not separate, products.
Revenue Impact of Product Relationships
These strategies don’t just improve AI performance – they also drive measurable revenue growth. Take Sur La Table, for example. By integrating AI-powered search with well-structured cross-sell and substitute mappings, they achieved an 11.5% increase in category Average Order Value (AOV) and a 7.6% boost in search AOV. This success stems from AI’s ability to deliver relevant recommendations right when customers are ready to act, transforming simple searches into opportunities for discovering multiple products.
The potential market impact is enormous. By 2028, AI-powered search is projected to influence $750 billion in U.S. consumer spending. Yet, many retailers currently capture only about 37% of their potential revenue expansion from existing customers. Cross-sell and substitute mappings can help close this gap by enabling AI to uncover subtle product relationships and adjust recommendations in real time based on inventory and user behavior. When AI can reason about what products go well together or serve as effective substitutes, every search query becomes a chance to expand revenue.
| Feature | Google Shopping Feed | OpenAI Product Feed |
|---|---|---|
| Primary Goal | Retrieval and Indexing | Semantic Reasoning and Understanding |
| Relationships | No direct equivalent in base feed | Explicit relationship_type and related_product_id |
| Data Structure | Multiple separate feeds (Inventory, Reviews, etc.) | Unified, single-record schema |
| Update Frequency | Typically 24 hours | Supports updates every 15 minutes |
This table highlights how AI-optimized feed standards prioritize relationship mapping over basic retrieval. The ability to refresh data every 15 minutes gives AI agents access to up-to-date information, allowing them to recommend substitutes that are actually in stock. Combined with structured relationship data, this real-time capability positions enriched product feeds as a critical advantage in the competitive landscape of AI-driven commerce.
Why Product Feed Enrichment Is the New SEO Layer for Retailers
From Metadata to Machine-Readable Product Intelligence
In the past, retailers focused on optimizing product titles, meta descriptions, and category pages for human search engines. But the game has changed. AI platforms now rely on structured data to process and understand products. Instead of analyzing entire webpages, platforms like ChatGPT work with structured product feeds to provide accurate answers and recommendations. This shift has turned product feed enrichment into a key element of SEO, essential for staying relevant in an AI-driven landscape.
Modern platforms require data delivered through APIs in formats like JSON-LD, updated frequently – often every 15 minutes. While Google’s product feed was designed to help with indexing, OpenAI’s feed standard is tailored for reasoning. It allows AI to explain why a product matters in a specific context, not just what it is. Keeping data fresh and accurate isn’t just good practice – it’s a trust signal that directly impacts whether your products are recommended. Retailers who rely on outdated or inaccurate data risk eroding customer trust by suggesting unavailable or out-of-stock items.
With AI-driven transactions on the rise and Gartner forecasting that by 2030, 20% of all purchases will happen through AI platforms or agents, enriched product feeds have become non-negotiable. They’re not just a technical requirement – they’re the foundation for staying visible and competitive in an AI-first world.
Long-Term Benefits of Enriched Product Feeds
Enriching product feeds offers more than just immediate improvements in machine readability. It sets the stage for long-term advantages that can redefine how retailers approach SEO. By unifying fragmented data – from core product details to inventory levels, regional pricing, and customer reviews – retailers create a single, reliable data source that AI platforms can consistently trust.
This unified approach enhances both accuracy and relevance over time. When AI platforms have access to detailed taxonomies, standardized terms, and well-structured product relationships, they can better match complex, niche queries that traditional keyword-based systems often miss. Right now, up to 30% of e-commerce searches fail due to incomplete product data. Enriched feeds help close this gap by providing the semantic depth AI needs to understand not just what a product is, but how it aligns with customer intent, specific use cases, and purchasing scenarios.
Another key advantage is the control enriched feeds give retailers over how their products appear on AI platforms. New feed standards include features like enable_search and enable_checkout, allowing brands to decide which products are discoverable and which can be purchased directly within a chat interface. This transforms product feeds into dynamic tools that not only improve customer experience but also drive revenue in AI-centric environments.
Final Takeaway: Retailers Need Product Intelligence, Not Just Product Data
AI-Ready Product Feeds as a Competitive Advantage
Product intelligence takes things to a whole new level – it’s not just about matching keywords or relying on human browsing habits anymore. Traditional product data was designed for basic keyword searches, but product intelligence is built for AI reasoning. This means large language models (LLMs) can now understand how products are used, compare them effectively, and even answer detailed conversational questions. With AI-driven orders skyrocketing 15x since 2025, retailers relying on outdated product feeds are being left behind.
“We’re no longer just optimizing for retrieval, we’re engineering for understanding.”
- Mike King, CEO, iPullRank
Here’s the thing: machine-parsable data isn’t the same as content meant for humans. AI agents can’t detect data buried in JavaScript or Liquid templates. Instead, structured, real-time intelligence delivered through APIs builds trust with AI systems. This trust leads to better recommendations and even enables features like native chat-based checkouts. For retailers, this means ensuring their catalogs are complete, accurate, and formatted for AI to interpret seamlessly.
This shift isn’t just a small improvement – it’s a game-changing advantage in the evolving world of AI commerce.
Preparing for the Future of AI Commerce
The era of AI search is here, and traditional product feeds just don’t cut it anymore. What retailers need is robust product intelligence. According to Gartner, by 2030, 20% of all transactions will happen through AI platforms or agents. Retailers who see feed enrichment as a simple data cleanup exercise risk falling behind. Instead, this requires a strategic investment in infrastructure. Enriched feeds don’t just improve AI search – they amplify results across SEO, voice commerce, and even social discovery.
Looking ahead, real-time, unified product intelligence will be the backbone of future transactions. One global retailer’s success story highlights how product intelligence isn’t just a technical upgrade – it’s a revenue-driving advantage that separates industry leaders from those struggling to keep up.
To stay competitive, retailers must move beyond fragmented and outdated feeds. Unified, real-time product intelligence systems are the way forward. Tools like Replenit use AI reasoning and synthetic data to fill gaps in catalogs, strengthen product relationships, and improve LLM compatibility. The future of retail visibility depends on treating product feeds as the cornerstone of AI readiness – not just another routine update.
FAQs
What makes a product feed “AI ready” for ChatGPT?
An “AI-ready” product feed is one that’s structured, accurate, and packed with detailed product attributes, relationships, and contextual information. This setup allows AI systems, like ChatGPT, to process and understand product data more effectively. With such a feed, AI can fill in missing details using synthetic data and identify connections, such as cross-sell opportunities or substitute products. These improvements make the data easier for machines to read and more useful for AI-driven discovery and recommendation systems.
Which product attributes most improve AI search visibility?
When it comes to boosting AI search visibility, detailed, structured, and semantically rich product attributes play a key role. These include elements like comprehensive product descriptions, clear specifications, practical use cases, and connections such as cross-sell or substitute mappings. By providing this level of detail, AI systems can better grasp the product’s context and relevance, leading to improved performance in AI-driven search and recommendation systems.
How often should enriched feeds be updated for AI commerce?
Enriched feeds need regular updates – preferably in real-time or at least frequently enough to capture changes in product details, stock levels, and connections. Keeping feeds current helps maintain peak performance and visibility in AI-powered commerce platforms.